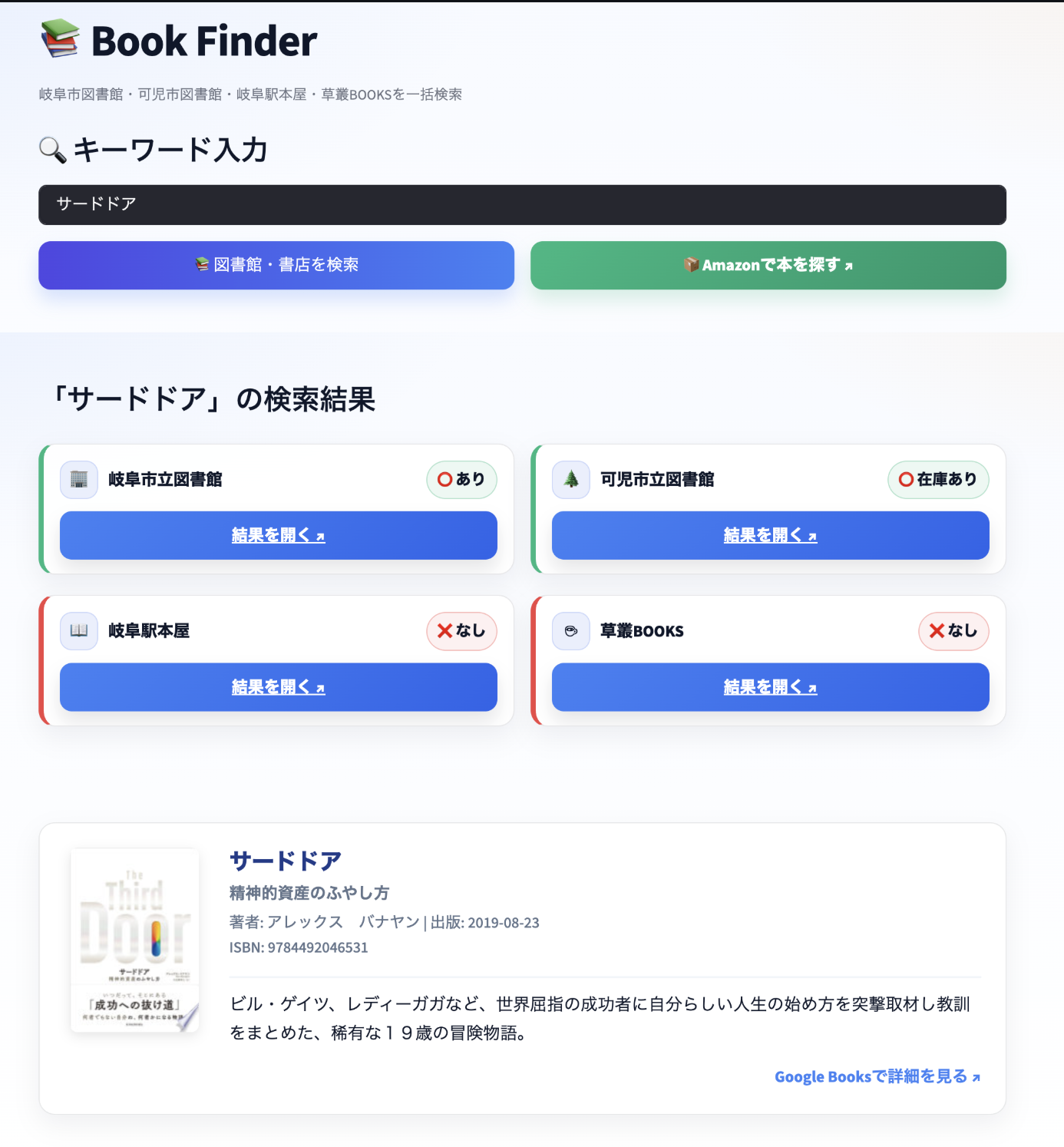
📚 プロジェクト概要
岐阜市立図書館・可児市立図書館・岐阜駅本屋・草叢BOOKSの4つの施設を一括検索できるWebアプリケーションです。 一度の検索で、4つの場所の在庫状況を同時に確認できます。
また、Amazonの検索結果ページへのリンクも生成され、購入の際の参考にできます。 さらに、Google Books APIを利用して、検索した書籍の概要(説明文)を自動で表示する機能も実装しています。
🎯 開発の目的
書籍を探す際、複数の図書館や書店のWebサイトを個別に検索するのは非効率です。 このアプリでは、1回の検索で4つの施設の在庫状況を同時に確認できるため、時間を大幅に節約できます。
- 複数サイトを行き来する手間を削減
- 在庫状況を一目で比較
- 各サイトの検索結果ページへ直接アクセス可能
- 書籍の概要を自動表示(Google Books API)
🛠️ 使用技術
💡 主な機能
- 一括検索: 4つの施設(岐阜市立図書館、可児市立図書館、岐阜駅本屋、草叢BOOKS)を同時検索
- 在庫状況表示: 各施設の在庫状況を「✅ あり」「❌ なし」「⚠️ 貸出中」で表示
- 検索結果リンク: 各サイトの検索結果ページへ直接アクセス可能(別タブで開く)
- Amazon連携: Amazonの検索結果ページへのリンクを自動生成
- 検索履歴機能: 過去5件の検索履歴を保存し、ボタンで再検索可能
- 書籍概要表示: Google Books APIから取得した説明文を自動表示
- レスポンシブデザイン: PC・スマートフォンの両方に対応
🔧 技術的な実装ポイント
1. Webスクレイピング
- User-Agent設定: サーバーからブロックされないよう、ブラウザを模倣
- セッション管理: requests.Session()でCookieを保持し、ログインが必要なサイトにも対応
- HTMLパース: BeautifulSoup4で検索結果ページを解析し、在庫状況を判定
2. サイトごとの違いへの対応
- 岐阜市立図書館: セッション初期化が必須(top.doでCookie取得)
- 可児市立図書館: OPWSRCH1.CSPにアクセスしてセッション開始
- 岐阜駅本屋: GETリクエストで直接アクセス可能
- 草叢BOOKS: 2段階(検索→在庫ページ生成)で処理
3. エラーハンドリング
- try-exceptでネットワークエラーをキャッチ
- タイムアウト設定(timeout=10秒)
- エラー時は「⚠️ エラー」と表示し、アプリを継続
4. Google Books API連携
- 検索キーワードでGoogle Books APIをリクエスト
- 取得した説明文を3行程度で表示
- 該当する書籍が見つからない場合は非表示
📈 開発で学んだこと
- Pythonによるスクレイピング技術: requests, BeautifulSoup4を使ったWebページ解析
- Streamlitの活用: PythonだけでWebアプリを構築する方法
- セッション管理: Cookieを使った認証・セッション維持
- API連携: Google Books APIを使った外部サービス連携
- エラーハンドリング: 実運用を想定した堅牢なエラー処理
- Streamlit Cloudへのデプロイ: クラウド環境での公開方法
⚠️ 注意事項
本プロジェクトは学習・個人利用目的で作成しています。 各サイトの利用規約を遵守し、短時間の連続アクセスは避けてください。 また、サイトのHTML構造が変更された場合、正常に動作しない可能性があります。